Data Literacy
Kelly McConville
Coffee and Treats with L&IT | Fall 2024
Bombardment of Data Arguments
Bombardment of Data Arguments
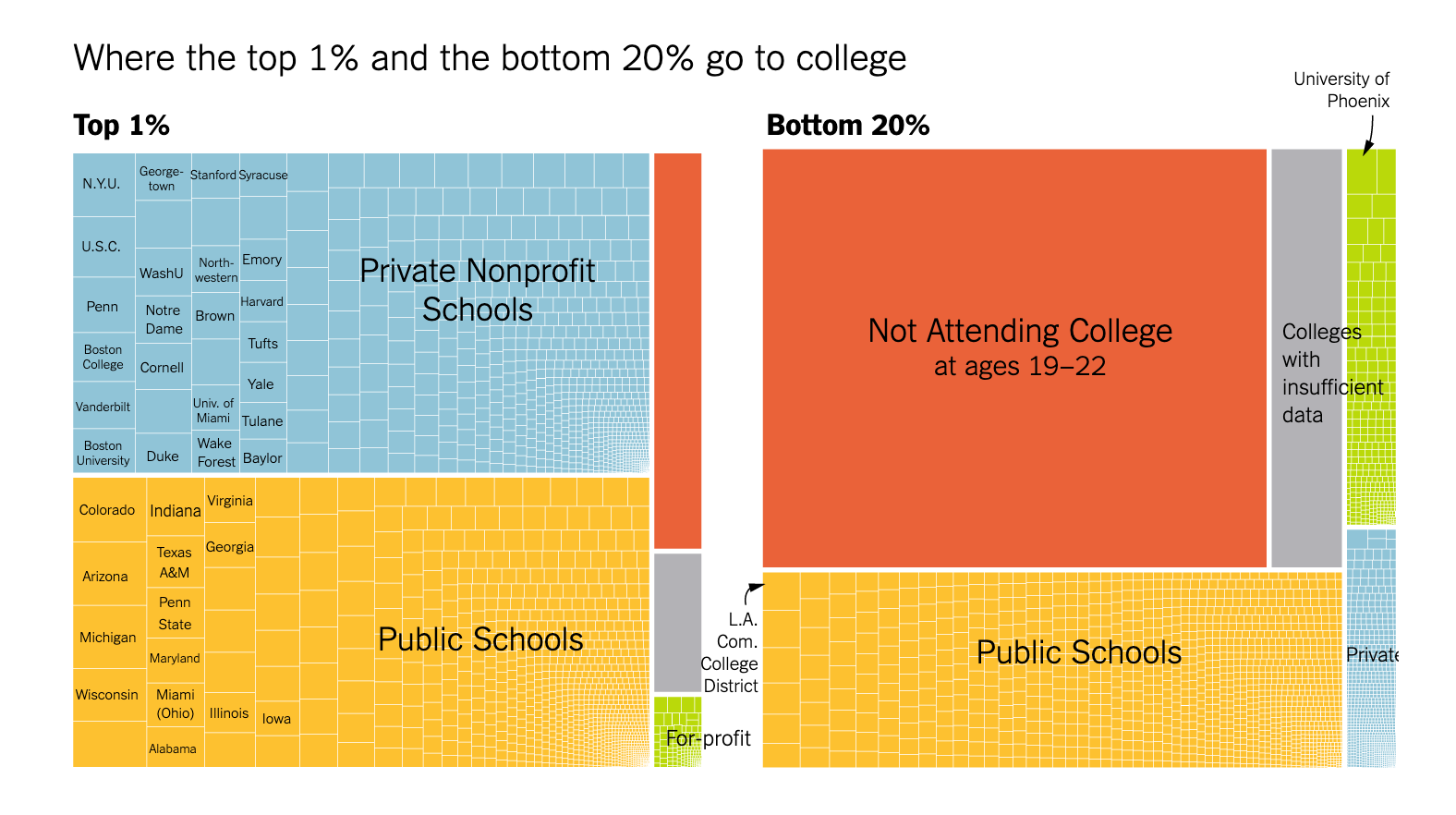
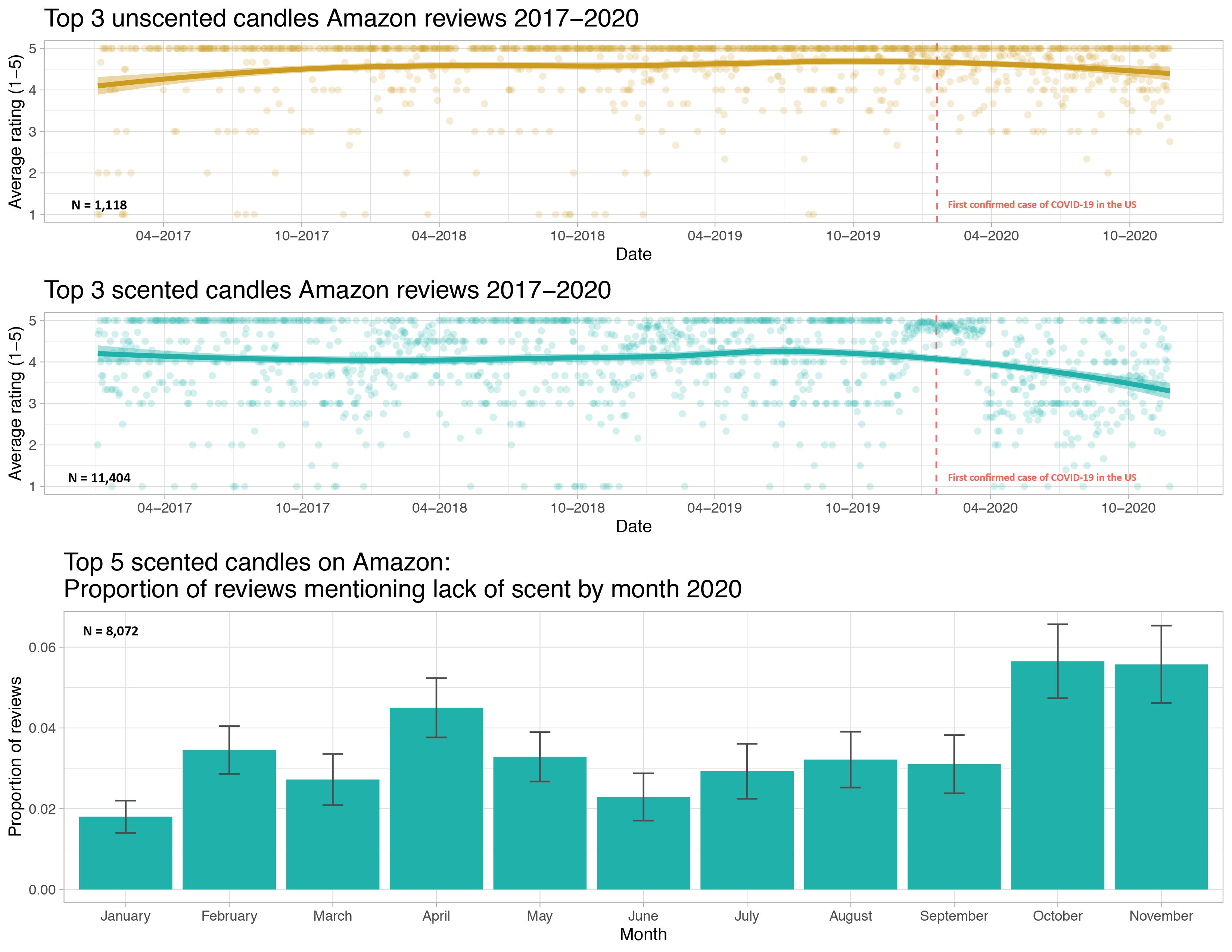
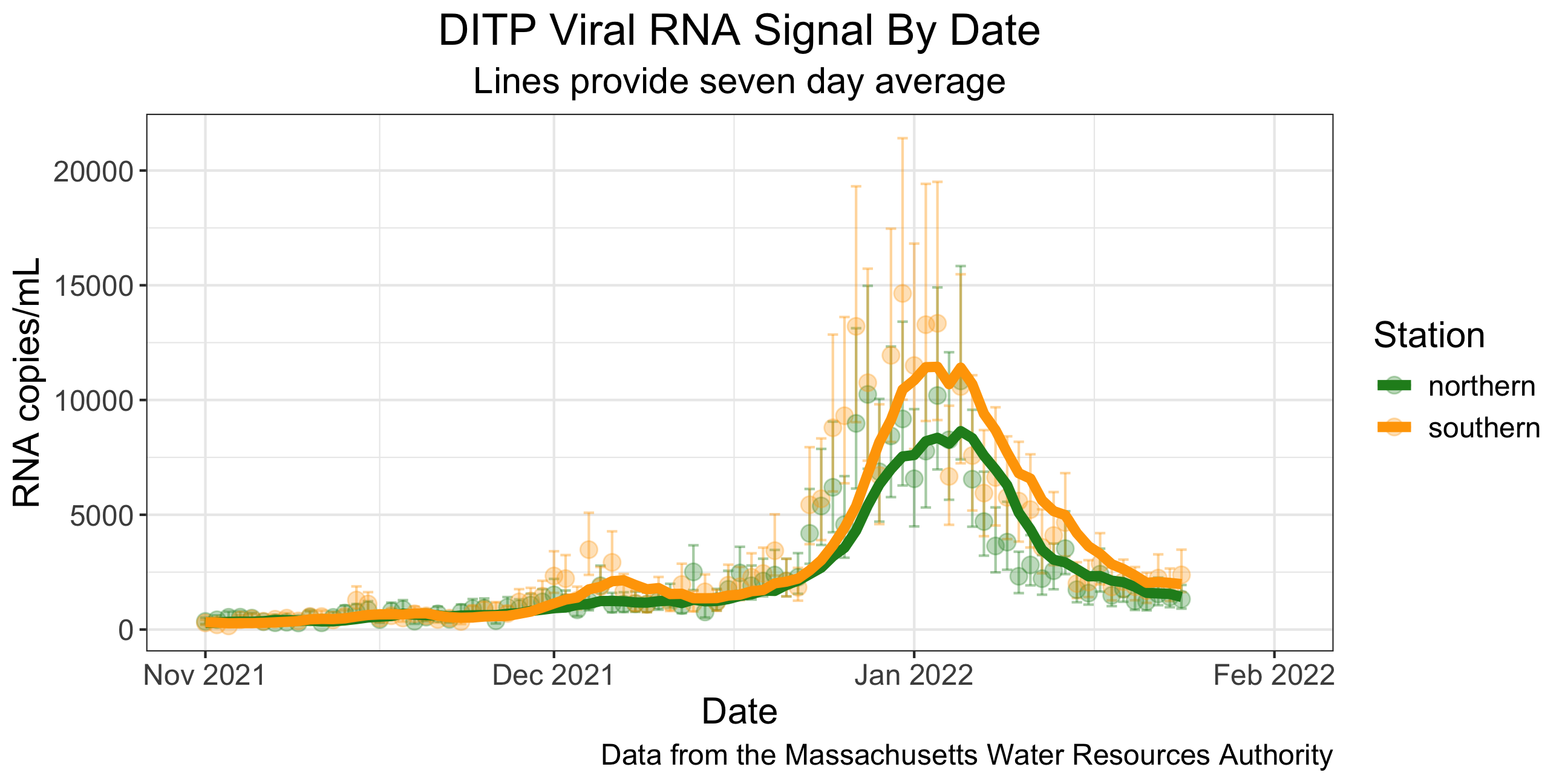
Example: Visualizing COVID Prevalence
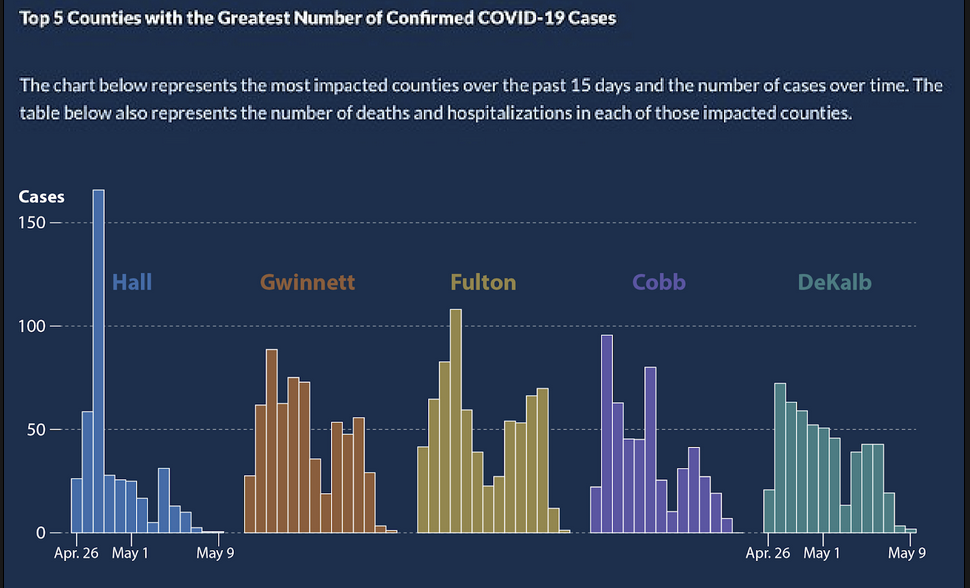
In May of 2020, the Georgia Department of Public Health posted the following graph:
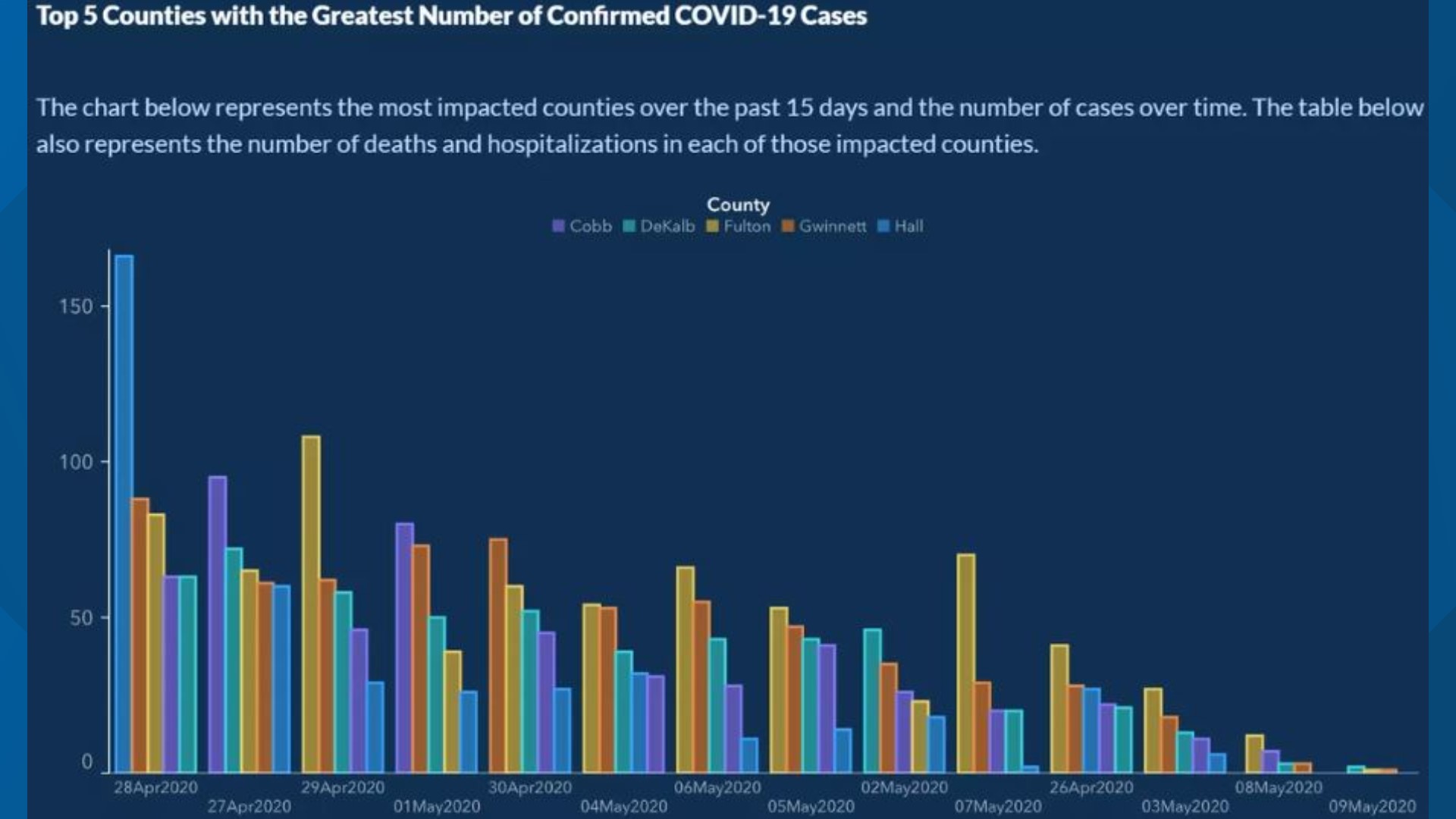
At a quick first glance, what story does the Georgia Department of Public Health graph appear to be telling?
What is misleading about the Georgia Department of Public Health graph? How could we fix this issue?
Example: Visualizing COVID Prevalence
After public outcry, the Georgia Department of Public Health said they made a mistake and posted the following updated graph:
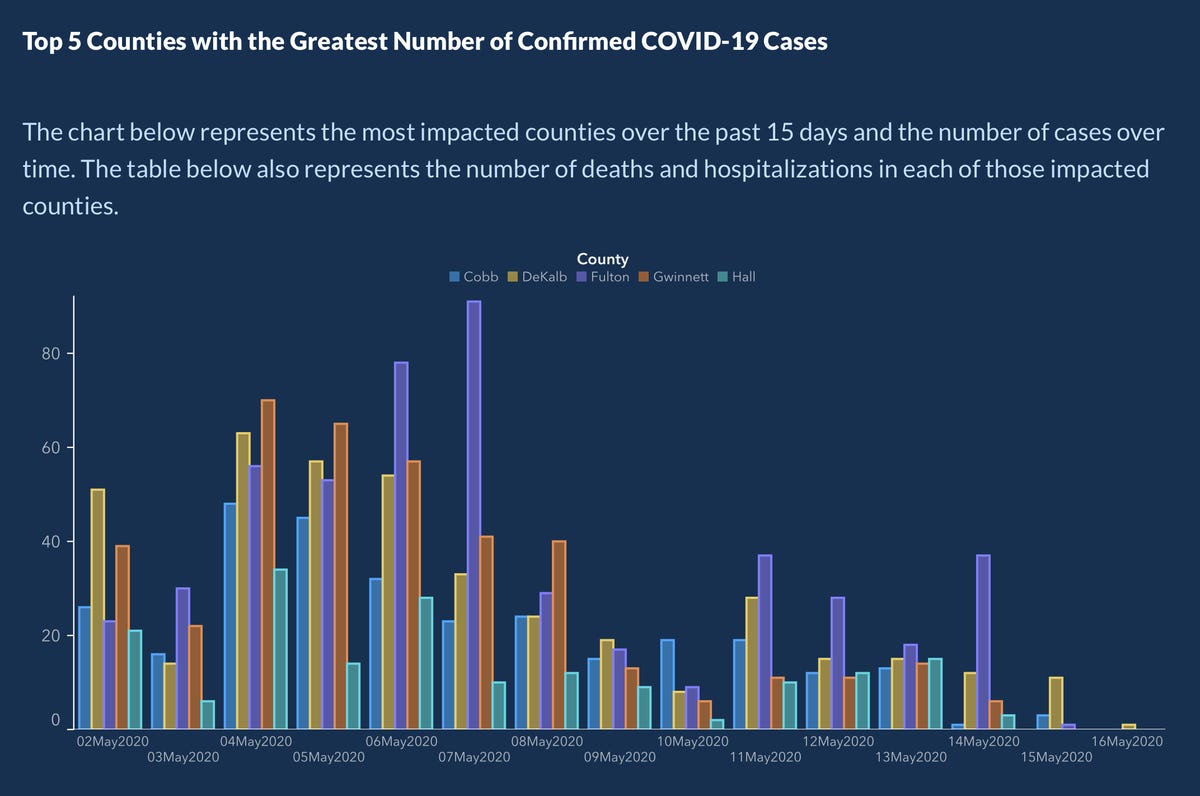
- How do your conclusions about COVID-19 cases in Georgia change when now interpreting this new graph?
Example: Visualizing COVID Prevalence
Alberto Cairo, a journalist and designer, created the second graph of the Georgia COVID-19 data:
A key principle of data visualization is to “help the viewer make meaningful comparisons”.
What comparisons are made easy by the lefthand graph? What about by the righthand graph?
From these graphs, can we get an accurate estimate of the COVID prevalence in these Georgian counties over this two week period?
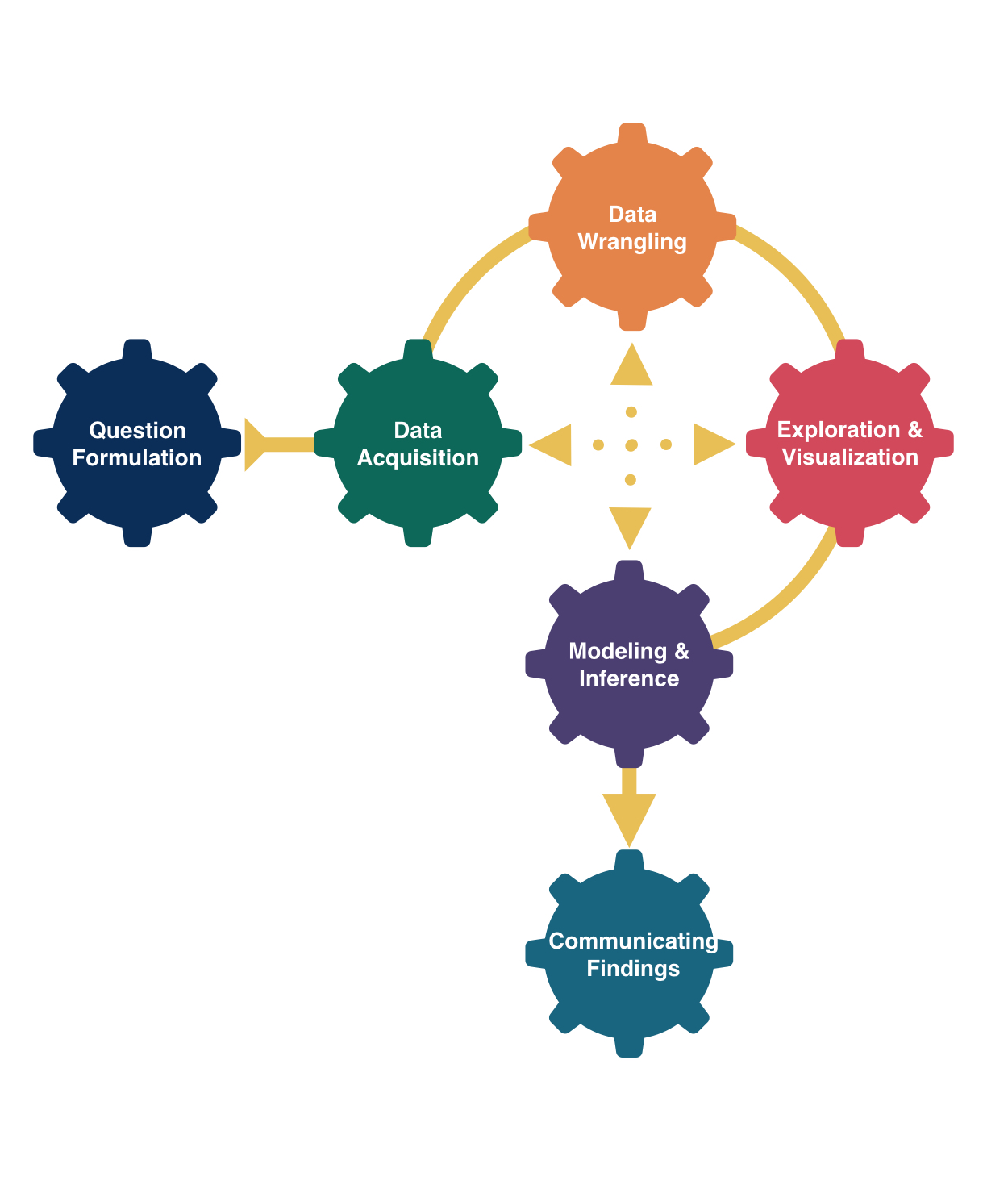
Data Analysis Process
Need to understand how “raw” data are processed into insights.
What choices were made at each step?
How do those choices impact the conclusions?